| Use of Cluster Computing in Simulation |
|---|
Article by: Larry
Mellon larry@maggotranch.com
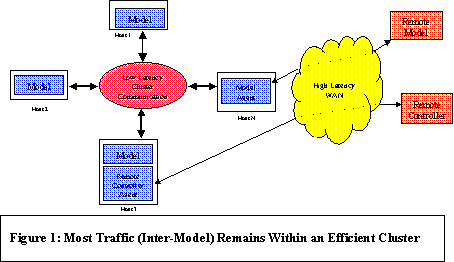
Distributed simulation has shown itself to be of use in many DoD application areas. However, scalability limitations have been encountered when executing very large scenarios with a high degree of shared information between distributed components of the simulation. These limitations have spawned a number of different research thrusts aimed at increasing the size of simulations supportable in a distributed environment. One promising approach is that of clustered computing, which promises increased performance and scalability at decreased cost by executing models in a communication-efficient central computing environment. The deployment of large-scale distributed simulation is simplified, and distributed access to the simulation is maintained. Clustering is used in Many Applications Clustered computing in its simplest form consists of a number of workstations linked via control software and a high-speed Local Area Network (LAN). Compute requests are given to a resource manager and are executed within the cluster. Users are isolated from the workstation(s) that process their request: speed and throughput are increased beyond what a single workstation could achieve. Distributed applications running across multiple hosts within a cluster is increasingly common. Clustering is used to support many classes of resource-intensive applications, from database servers to numerical analysis programs. Clusters are an attractive alternative for certain classes of applications. While a cluster cannot achieve the inter-processor communication speeds of a parallel supercomputer, many applications do not need such communication performance. The amount of memory consumed by the application and the processor speeds available across supercomputers and workstations should also be considered. To date, the processor speeds and addressable memory achieved within the highly competitive workstation market quickly outstrip the processor speeds and memory per processor used in a supercomputer implementation soon after the supercomputer reaches the market. Low Latency Improvements to Clustering A recent trend in cluster computing has been the transition of communication technology from the supercomputing world to the workstation and PC markets. Joining the established SCRAMnet product in providing low latency, high bandwidth communication between individual computers are such technologies as Myrinet and SCI. Application to application latencies (each resident on a separate workstation) on the order of two to eight microseconds have been observed. This compares quite favorably with Wide Area Network (WAN) latencies on the order of hundreds to thousands of microseconds. While the underlying technology and interfaces differ between these low latency products, all benefit substantially from directly mapping the communication device drivers into application memory space. This bypasses the need to copy data into the kernel, eliminating kernel overhead and greatly reducing host CPU costs for servicing a communication request.Distributed Simulation via Clustered Computing Clustering works well for many application areas, but how does it apply to distributed simulation? This question forces a closer examination of what ‘distributed’ really means. Does it imply that all models must be capable of execution anywhere in the distributed system, or may we assume that models can be bound to a single site? What of the simulation users? Must they be co-located with the models, or may the users and models be located anywhere in the distributed system? In fact, many current simulation systems may be considered cluster-based to one extent or another. A paper by Fred Wieland, titled "Parallel Simulation for Aviation Applications," (to appear in Proceedings of the 1998 Winter Simulation Conference, December, 1998, Washington, D.C.) describes a model constructed and supported by the Mitre Corporation for the Federal Aviation Administration’s aircraft traffic modeling. All model execution is done at a central site via parallel processors. Users configure the models and access results via the web. The Joint Precision Strike Demonstration infrastructure supports large-scale training exercises by using a group of co-located workstations linked together via an ATM-based LAN. Ed Powell’s paper "The Joint Precision Strike Demonstration Simulation Architecture" (1996, 14th DIS Workshop) describes the configuration techniques and gateways used to minimize communication loads within the system and the connections out to remote trainees. From these and similar systems, ‘distributed’ simulation clearly encompasses a wide range of simulation use cases. But what of the popular DIS-style training exercises, where models are co-located with model controllers or trainees at physically separate response sites? Moving key personnel from response sites to a central location for a single exercise is generally not feasible. The use of clustering in such cases would require a shift in how all components of the system – users, models, computers, and networks – are linked together. Under an ideal clustered computing scenario, the simulation users would remain fully distributed and connect into the cluster via standard WAN technology. The bulk (if not all) of the models would be executed within the cluster environment, communicating via a low latency, high bandwidth LAN.
The benefits to the models are clear: very low latency between interacting models improves accuracy. Infrastructure gains are also appealing: model to model traffic forms a very large portion of a distributed simulation’s communication load. Gathering the majority of such traffic in a cluster significantly lowers the demand for expensive WAN connectivity and the resources required to maintain WAN connectivity in the face of high, multicast-intensive traffic loads. Cluster infrastructure implementations, having fewer connectivity issues to address, should be easier to construct than similar WAN-based implementations. Similarly, areas such as administration of hardware and software configuration control are greatly simplified when the majority of resources are at a single site. For systems with security constraints, containing all model to model interactions within a single, secure site simplifies many problems with multi-level security. Standard secure gateways may be used to pass data to and from WAN-connected users of the clustered models, with lower traffic loading on the gateway than would be the case for most WAN-connected models. Of course, nothing comes for free. Clustered computing provides a number of significant advantages to a distributed simulation system, but what costs are imposed? The most notable change is the increased latency between models and their controllers. Previously co-located, users must now observe and control models separated by WAN latencies. Fortunately, techniques such as dead reckoning (or predictive contracts) have been shown to smooth jitter and hide latencies between WAN-distributed models: they should also work for linking models and controllers. One approach is to place an agent between the controller and the model. The controller (or any user interfacing with the system) informs the agent of the data that is required for screen display. The agent accesses the cluster via a WAN link and obtains the required data. Predictive contract optimizations may then be done on the WAN traffic to hide the latency between users and models. This approach of remote users interacting with a central, real-time application is increasingly common in the Internet gaming community, which has strong infrastructure similarities to training simulations. Examples may be found at www.kaon.com, www.unreal.com, and www.imagiconline.com.Industry Standard on the Horizon Industry interest in low latency clusters is growing. Performance results from research projects such as Beowulf are very encouraging, although maximizing performance still requires patience and a careful touch. A group of leading vendors has begun promoting a System Area Network (SAN) concept, backed by the Virtual Interface (VI) Architecture. VI would provide a standard API to a diverse set of low latency technologies.While an industry standard will definitely increase the user base for SANs and thus their availability to the distributed simulation community, concerns exist that the emerging SAN standard may not meet the specialized communication needs of distributed simulation. In particular, the heavy use of Internet Protocol (IP) multicast by some distributed simulations may cause problems. Multicast is particularly valuable in simulations where large quantities of data are shared between several host computers. Multicast’s support of ‘one transmission, multiple receptions’ lowers communication costs on host computers, reduces bandwidth requirements, and allows network-level filtering of unwanted data. However, current SAN solutions are focused on point to point traffic, not point to multi-point. This may require a change in the style of communication used to link distributed simulation host computers. ASTT is investigating alternate Data Distribution Management implementation options for low latency clusters, and similar communication issues were addressed in the SF Express project.Clustering Within the HLA The High Level Architecture Run-Time Infrastructure (HLA RTI) may play a significant role in cluster-based simulation. First, the RTI paradigm provides natural connectivity to remote models for cases where hosting all modeling at a central cluster is not practical. Second, remote operators and / or remote devices may also connect into the clustered models via the RTI. Many such systems are likely to already support RTI connectivity for other functions. Two other options involve cluster-optimized implementations of the RTI itself. Cluster-optimized RTIs would allow efficient, clustered execution of models with little to no change required in the simulation. Under one approach, a cluster-optimized RTI would be constructed, optimizing the communication-intensive Data Distribution Management and Time Management functions of the RTI for the style of communication possible within a cluster. No change would be required at the API level to support such optimizations, and models would transparently gain the advantage of efficient clustered execution. Connections out to remote users and / or models would be done via a bridge federate, connected to both the existing WAN-RTI and the cluster-optimized RTI. A second RTI / cluster option involves the subsumption of cluster technology into the RTI as a whole. Under this strategy, internal RTI modules become cluster-savvy and federations map their models to federate hosts both inside and outside the cluster. When communicating between federates hosts within a cluster, cluster-efficient communication is used by the RTI. Similarly, the RTI would use standard WAN communication for hosts exchanging data outside of the cluster. While the RTI-internal implementation option is more complex to the builder of an RTI, the result should be simpler use of clustering for a federation designer. Models could be easily re-mapped across the available set of federation hosts. Shared resource centers may be started, where a cluster of workstations is available via the RTI to speed execution of any federation. Load balancing at the federation level, where a subset of federates which communicate heavily with each other are mapped to the same cluster, becomes easier and reduces load on the network as a whole. The extra overhead of a bridge federate is also avoided. What Does the Future Hold for Clustering? Cluster computing appears to hold great promise in supporting large scale distributed simulation. Advantages over fully (WAN) distributed execution exist from both hardware cost and performance viewpoints, while support is maintained for distributed users interacting with clustered models. Increased industry support for low latency clusters will help in availability and performance, but restrictions within the API (and the supporting hardware) may require a departure from the current multicast-oriented data distribution strategies. However, latency and bandwidth performance continue to improve in the Ethernet and ATM worlds, providing the basis for very low cost clusters with multicast support. To ease the transition of clustering into the distributed simulation community, implementations of the HLA RTI standard should be optimized to transparently provide cluster-based performance to federation designers. Author Biography Larry Mellon is a senior computer scientist and branch manager with Science Applications International Corporation (SAIC). He received his B.Sc. degree from the University of Calgary and has worked in the area of parallel and distributed simulation infrastructure for over ten years. His research interests include parallel simulation and distributed systems.
|
| Close |